Database Management System Question Bank CAE-3
Answers
- Database Management System Question Bank CAE-3
- Answers
- 1. Elaborate in detail DBMS 2 tier and 3 tier architecture
- 2. Brief in detail: Relational, Entity-Relationship data model
- 3. Brief in detail: Object-based , Semistructured data model
- 4. Design an ER diagram of: Library Management system
- 5. Design an ER diagram of: Railway reservation system
- 6. Design an ER diagram of: Airline reservation system
- 7. Design an ER diagram of: Hotel Management system
- 8. Design an ER diagram of: Hospital Management system
- 9. Explain Relational Database design in detail
- 10. State and explain with suitable example built in functions in database
- 11. Describe View and types in SQL in detail
- 12. Write 4 queries to use : group by, having, order by functions
- 13. State concept of JOIN .Explain types of join with suitable examples
- 14. Define constraint. What SQL constraints do you know?
- 15. With suitable examples explain use of aggregate functions
- 16. Elaborate in detail DDL \& DML commands with suitable examples
- 17. What types of SQL subqueries do you know?Explain with suitable example
- 18. Define following terms :Primary key, Foreign key ,Unique key in brief
- 19. Explain CRUD operations in DBMS in detail with suitable examples
- 20. Describe Data mining process in detail with suitable example
- 21. Brief in detail: NoSQL database
- 22. Elaborate in detail recent advancements in database management system
1. Elaborate in detail DBMS 2 tier and 3 tier architecture
2-Tier Architecture
- The 2-Tier architecture is same as basic client-server. In the two-tier architecture, applications on the client end can directly communicate with the database at the server side. For this interaction, API's like: ODBC, JDBC are used.
- The user interfaces and application programs are run on the client-side.
- The server side is responsible to provide the functionalities like: query processing and transaction management.
- To communicate with the DBMS, client-side application establishes a connection with the server side.
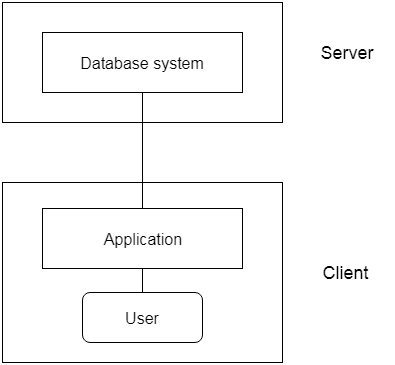
Fig: 2-tier Architecture
3-Tier Architecture
- The 3-Tier architecture contains another layer between the client and server. In this architecture, client can't directly communicate with the server.
- The application on the client-end interacts with an application server which further communicates with the database system.
- End user has no idea about the existence of the database beyond the application server. The database also has no idea about any other user beyond the application.
- The 3-Tier architecture is used in case of large web application.
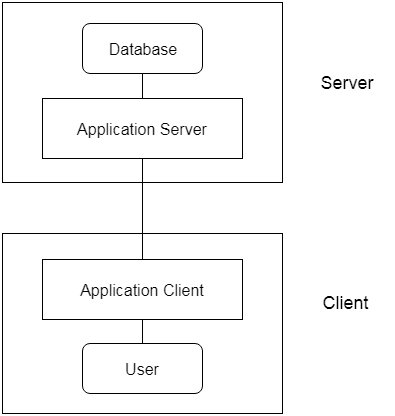
2. Brief in detail: Relational, Entity-Relationship data model
Relational Data Model:
The Relational Data Model is a fundamental framework for organizing and managing data in a relational database management system (RDBMS). It was introduced by Edgar Codd in 1970 and is widely used in modern database systems. Here's a more detailed explanation:
-
Tables: In the Relational Data Model, data is organized into tables, which are also referred to as relations. Each table consists of rows (tuples) and columns (attributes). The rows represent individual records, while the columns represent the attributes or properties of those records.
-
Keys: Each table typically has a primary key that uniquely identifies each record within the table. Additionally, tables can have foreign keys, which establish relationships between tables by referencing the primary key of another table.
-
Data Integrity: The relational model enforces data integrity through constraints. Common constraints include primary key constraints (to ensure uniqueness), foreign key constraints (to maintain referential integrity), and various other rules for data validation.
-
SQL (Structured Query Language): To interact with relational databases, SQL is used. SQL allows users to perform operations like inserting, updating, querying, and deleting data from tables. It also supports complex queries for retrieving and manipulating data.
-
Normalization: The relational model promotes data normalization to reduce data redundancy and improve data integrity. This involves breaking down data into separate tables to eliminate data duplication and minimize update anomalies.
Entity-Relationship (ER) Data Model:
The Entity-Relationship Data Model is a conceptual and visual representation of the data and its relationships within an organization or system. It's often used to design databases and understand the structure of data. Here's a more detailed explanation:
-
Entities: In the ER model, entities are real-world objects, concepts, or things that are relevant to the system being modeled. Each entity is represented as a rectangular box in the ER diagram and corresponds to a table in the relational database.
-
Attributes: Attributes are properties or characteristics of entities. They are depicted as ovals connected to the entity boxes in the ER diagram. In a relational database, attributes correspond to columns in a table.
-
Relationships: Relationships describe how entities are connected to each other. They are depicted as diamond shapes in the ER diagram and establish connections between entities. In a relational database, relationships are often implemented through foreign keys.
-
Cardinality: Cardinality defines the number of instances of one entity that are related to the number of instances of another entity in a relationship. Common cardinalities include one-to-one, one-to-many, and many-to-many.
-
ER Diagrams: ER diagrams visually represent the data model and its components. They help database designers and stakeholders understand the structure of the data and how entities relate to each other.
3. Brief in detail: Object-based , Semistructured data model
Object-Based Data Model:
The Object-Based Data Model is a data model that represents data using the principles of object-oriented programming. It extends the relational data model to include object-oriented concepts such as encapsulation, inheritance, and polymorphism. Here's a more detailed explanation:
-
Objects: In the Object-Based Data Model, data is organized into objects. An object is an instance of a user-defined class and combines data (attributes) and behavior (methods) into a single unit. These objects are similar to the objects in object-oriented programming languages like Java or C++.
-
Classes: Classes define the structure and behavior of objects. They serve as blueprints for creating objects. Each class defines a set of attributes and methods that its objects will have.
-
Inheritance: Inheritance allows for the creation of new classes by inheriting attributes and methods from existing classes. This promotes code reuse and the modeling of "is-a" relationships between classes. For example, you can have a base class like "Vehicle" and derive specific classes like "Car" and "Motorcycle" from it.
-
Encapsulation: Encapsulation ensures that the data and behavior of an object are encapsulated within the object, and external entities can only interact with the object through its defined methods. This provides data security and abstraction.
-
Polymorphism: Polymorphism enables objects of different classes to be treated as objects of a common base class. This allows for flexibility and dynamic dispatch of methods.
-
Complex Data Structures: Object-Based Data Models are useful for representing complex data structures, including nested objects, arrays, and more, which can be challenging to represent in traditional relational databases.
Semi-Structured Data Model:
The Semi-Structured Data Model is a flexible data model that does not impose a rigid structure like the relational model but still provides some structure and organization. It is commonly used for data that doesn't fit neatly into tables with fixed schemas, such as XML and JSON data. Here's a more detailed explanation:
-
Flexible Structure: Semi-structured data does not adhere to a fixed schema, meaning that different records or documents can have varying structures. Each data item can have different attributes or elements.
-
Self-Descriptive: Semi-structured data often includes metadata or information about the data itself. This self-descriptive nature allows data to be more flexible and adaptable to changing requirements.
-
Hierarchical: Semi-structured data is often organized hierarchically, making it suitable for representing data with parent-child relationships. XML and JSON, for example, use hierarchical structures.
-
NoSQL Databases: Many NoSQL databases, such as document databases and key-value stores, support semi-structured data. They allow you to store and query data without a predefined schema.
-
Schema Evolution: Semi-structured data is well-suited for scenarios where the schema of the data can evolve over time without requiring a disruptive change to existing data.
-
Query Flexibility: While querying semi-structured data can be more complex compared to relational databases, it offers greater flexibility in accommodating data that doesn't fit into a rigid, tabular structure.
4. Design an ER diagram of: Library Management system

5. Design an ER diagram of: Railway reservation system

6. Design an ER diagram of: Airline reservation system
7. Design an ER diagram of: Hotel Management system

8. Design an ER diagram of: Hospital Management system
9. Explain Relational Database design in detail
Relational database design is a structured and systematic process of defining the structure and organization of a relational database, which is a collection of tables that store data. A well-designed relational database ensures data integrity, performance, and efficient data retrieval. Here's a detailed explanation of the steps involved in the relational database design process:
-
Requirements Analysis:
- Begin by understanding the data requirements of the system or application for which you are designing the database. This involves talking to stakeholders, identifying data sources, and defining the purpose of the database.
- Determine the entities (objects or concepts) that need to be represented in the database. This often involves creating an Entity-Relationship Diagram (ERD) to visualize the entities and their relationships.
-
Data Modeling:
- Create an Entity-Relationship Diagram (ERD) to represent the entities, attributes, and relationships in the system. In an ERD:
- Entities are represented as boxes.
- Attributes are represented as ovals connected to entities.
- Relationships are represented as diamond shapes connecting entities.
- Create an Entity-Relationship Diagram (ERD) to represent the entities, attributes, and relationships in the system. In an ERD:
-
Normalization:
- Normalize the data to reduce data redundancy and improve data integrity. Normalization is the process of organizing data in tables to minimize data duplication and prevent anomalies.
- Normal forms like 1NF, 2NF, 3NF, BCNF, and 4NF are used to guide the normalization process. Each normal form addresses specific types of data redundancy and dependencies.
-
Table Design:
- Based on the ERD and the results of normalization, design the tables that will store the data. Each entity in the ERD corresponds to a table in the database.
- Define the columns (attributes) for each table and specify data types, constraints, and the primary key.
-
Key Selection:
- Choose primary keys for each table to ensure that each row can be uniquely identified. Primary keys are often based on a single attribute, but composite keys can be used for more complex cases.
-
Establish Relationships:
- Define foreign keys to establish relationships between tables. Foreign keys link records in one table to related records in another table.
- Specify the cardinality of relationships (one-to-one, one-to-many, or many-to-many).
-
Integrity Constraints:
- Define integrity constraints to ensure data accuracy and consistency. Common constraints include:
- Unique constraints to enforce uniqueness of values.
- Check constraints to validate data against a specific condition.
- Referential integrity constraints to maintain the consistency of relationships between tables.
- Define integrity constraints to ensure data accuracy and consistency. Common constraints include:
-
Indexing:
- Create indexes on columns that are frequently used in search and retrieval operations. Indexes improve query performance by allowing the database system to find data more quickly.
-
Data Types and Data Validation:
- Choose appropriate data types for columns to ensure data accuracy and efficiency.
- Implement data validation rules to enforce data quality.
-
Normalization Review:
- Review the normalization process to ensure that the database design adheres to the desired normal form and that there is no unnecessary redundancy.
10. State and explain with suitable example built in functions in database
-
In SQL, built-in functions are a set of predefined functions that can be used to perform various operations on data in a database. These functions can be categorized into several groups, including mathematical functions, string functions, date and time functions, aggregate functions, and more. Here, I'll explain some commonly used built-in functions in SQL with suitable examples:
-
Mathematical Functions:
-
ABS(): Returns the absolute value of a number.Example:
sql
-
-
-
SELECT ABS(-10); -- Returns 10-
ROUND(): Rounds a number to a specified number of decimal places.Example:
sql
-
SELECT ROUND(3.14159, 2); -- Returns 3.14
-
-
String Functions:
-
CONCAT(): Concatenates two or more strings.Example: sql -
SELECT CONCAT('Hello, ', 'World!'); -- Returns 'Hello, World!' -
SUBSTRING(): Returns a substring from a given string.Example:
sql
-
SELECT SUBSTRING('Database', 4, 4); -- Returns 'abas'
-
-
Date and Time Functions:
-
NOW(): Returns the current date and time.Example: sql -
SELECT NOW(); -- Returns the current date and time -
DATEADD(): Adds a specified time interval to a date.Example:
sql
-
SELECT DATEADD(DAY, 7, '2023-10-31'); -- Adds 7 days to the date
-
-
Aggregate Functions:
-
COUNT(): Returns the number of rows in a result set.Example: sql -
SELECT COUNT(*) FROM Customers; -- Returns the number of customers -
SUM(): Returns the sum of values in a numeric column.Example:
sql
-
SELECT SUM(Price) FROM Orders; -- Returns the total order value
-
-
Conversion Functions:
-
CAST(): Converts one data type to another.Example: sql
SELECT CAST('42' AS INT); -- Converts the string '42' to an integer -
11. Describe View and types in SQL in detail
-
In SQL, a view is a virtual table created by a query, and it allows users to access and manipulate data without directly modifying the underlying tables. Views provide a way to present a subset of the data or present the data in a different format, making it easier to manage and query the database. There are several types of views in SQL, each with specific characteristics and use cases. Here, I'll describe the concept of views and then explain some common types of views in detail.
Basic View Concepts:
- A view is defined using a SELECT statement and is stored as a virtual table in the database.
- Views are typically used to restrict access to certain columns or rows of a table, provide an abstracted layer over complex joins, or simplify querying for end-users.
- Views do not store data themselves; they are simply saved query results.
- Users can query views just like they query tables, and views can be used as data sources for other views or as part of more complex queries.
Common Types of Views:
-
Simple View:
- A simple view is based on a single table or can join multiple tables but doesn't contain any aggregate functions or GROUP BY clauses.
- It is created by selecting a subset of columns or rows from one or more tables.
- Simple views are often used to hide certain columns or to provide a simplified perspective on the data.
Example of creating a simple view:
sql
-
CREATE VIEW EmployeeView AS SELECT EmployeeID, FirstName, LastName FROM Employees;-
Complex View:
-
A complex view can contain multiple tables, joins, aggregate functions, and GROUP BY clauses.
- They are used for more advanced data manipulation and often serve as a way to create a consolidated report.
Example of creating a complex view:
sql
-
CREATE VIEW SalesSummary AS SELECT Product.Name, SUM(Sale.Quantity) AS TotalSold FROM Sales JOIN Product ON Sales.ProductID = Product.ProductID GROUP BY Product.Name; -
Indexed View (Materialized View):
-
An indexed view is a type of view that stores the result set in a materialized form, allowing for faster query performance.
- The data in an indexed view is precomputed and stored, so it's especially useful for complex queries involving aggregations or joins.
Example of creating an indexed view:
sql
-
CREATE VIEW MaterializedSales AS SELECT Product.Name, SUM(Sale.Quantity) AS TotalSold FROM Sales JOIN Product ON Sales.ProductID = Product.ProductID GROUP BY Product.Name WITH SCHEMABINDING -
Partitioned View:
-
A partitioned view is used to combine data from multiple, similar tables into a single virtual table, presenting a unified view to the users.
- It can be helpful in cases where data is partitioned across multiple tables, such as for time-based data partitioning.
Example of creating a partitioned view:
sql
-
CREATE VIEW MonthlySales AS SELECT * FROM JanuarySales UNION ALL SELECT * FROM FebruarySales UNION ALL -- ... (continue for other months) -
Read-Only View:
-
A read-only view is a view that's defined with the
WITH CHECK OPTIONclause, which ensures that updates, inserts, or deletes can't be performed through the view. - It is used to enforce data integrity and prevent modifications to the data via the view.
Example of creating a read-only view:
sql
-
CREATE VIEW ReadOnlyCustomers AS SELECT * FROM Customers WITH CHECK OPTION;
12. Write 4 queries to use : group by, having, order by functions
-
Group By and Order By:
Query: Retrieve the total quantity sold for each product category and order the result by the total quantity in descending order.
sql
-
SELECT Category, SUM(Quantity) AS TotalQuantity FROM Sales GROUP BY Category ORDER BY TotalQuantity DESC;In this query, we first group the sales data by product category and calculate the total quantity sold in each category. Then, we order the result in descending order based on the total quantity.
-
Group By, Having, and Order By:
Query: Find the average price of products in each category, but only include categories where the average price is greater than $50, and order the result by the average price in ascending order.
sql
-
SELECT Category, AVG(Price) AS AvgPrice FROM Products GROUP BY Category HAVING AvgPrice > 50 ORDER BY AvgPrice;This query groups products by category, calculates the average price for each category, and uses the
HAVINGclause to filter out categories with an average price less than $50. Finally, it orders the result by average price in ascending order. -
Group By with Count:
Query: Count the number of employees in each department and order the result by the number of employees in descending order.
sql
-
SELECT Department, COUNT(EmployeeID) AS EmployeeCount FROM Employees GROUP BY Department ORDER BY EmployeeCount DESC;This query groups employees by department, counts the number of employees in each department, and then orders the result by the employee count in descending order.
-
Group By with Date and Having:
Query: Find the total sales amount for each salesperson who has generated more than $10,000 in sales for the current year (2023), and order the result by the total sales amount in descending order.
sql
SELECT Salesperson, SUM(Amount) AS TotalSales
FROM Sales
WHERE YEAR(SaleDate) = 2023
GROUP BY Salesperson
HAVING TotalSales > 10000
ORDER BY TotalSales DESC;
In this query, we filter sales data for the current year (2023), group the sales by salesperson, calculate the total sales amount for each salesperson, use the HAVING clause to filter for salespersons with total sales over $10,000, and finally, order the result by total sales amount in descending order.
13. State concept of JOIN .Explain types of join with suitable examples
-
In SQL, a JOIN operation combines rows from two or more tables based on a related column between them. JOINs are used to retrieve and display data from multiple tables in a single result set. The common column(s) used for joining tables is referred to as a join condition. JOINs are a fundamental concept in relational databases and are used to establish relationships between tables, enabling more complex and meaningful queries.
Types of JOINs in SQL with Examples:
There are several types of JOIN operations in SQL, each with its own purpose and behavior. Here are the most commonly used types of JOINs along with examples:
-
INNER JOIN:
- An INNER JOIN returns only the rows that have matching values in both tables.
- It filters out rows that do not have corresponding data in both tables.
Example: Suppose we have two tables:
CustomersandOrders, and we want to retrieve a list of customers and their associated orders.sql
-
SELECT Customers.CustomerName, Orders.OrderDate FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;-
LEFT JOIN (or LEFT OUTER JOIN):
-
A LEFT JOIN returns all rows from the left table and the matched rows from the right table.
- If there are no matches in the right table, NULL values are returned for columns from the right table.
Example: If we want to retrieve a list of all customers and their orders, including customers with no orders:
sql
-
SELECT Customers.CustomerName, Orders.OrderDate FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID; -
RIGHT JOIN (or RIGHT OUTER JOIN):
-
A RIGHT JOIN returns all rows from the right table and the matched rows from the left table.
- If there are no matches in the left table, NULL values are returned for columns from the left table.
Example: If we want to retrieve a list of all orders and the associated customer names, including orders with no customers:
sql
-
SELECT Customers.CustomerName, Orders.OrderDate FROM Customers RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID; -
FULL JOIN (or FULL OUTER JOIN):
-
A FULL JOIN returns all rows when there is a match in either the left or right table.
- It includes all rows from both tables, filling in NULL values where there are no matches.
Example: To retrieve a list of all customers and their orders, including customers with no orders and orders with no customers:
sql
-
SELECT Customers.CustomerName, Orders.OrderDate FROM Customers FULL JOIN Orders ON Customers.CustomerID = Orders.CustomerID; -
14. Define constraint. What SQL constraints do you know?
-
In SQL, a constraint is a rule or condition that is applied to data in a database to maintain the integrity, accuracy, and consistency of that data. Constraints define limits and requirements for the values that can be inserted, updated, or deleted in a database table. They ensure that the data stored in the database meets certain criteria and follows specific rules. There are several types of constraints in SQL:
-
Primary Key Constraint:
- A primary key constraint uniquely identifies each row in a table.
- It ensures that a specific column or set of columns contains unique values and does not allow NULL values.
- There can be only one primary key constraint per table.
Example:
sql
-
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName VARCHAR(50), LastName VARCHAR(50) );-
Unique Constraint:
-
A unique constraint ensures that values in a specified column or set of columns are unique, similar to a primary key.
- However, unlike a primary key, a unique constraint allows NULL values.
Example:
sql
-
CREATE TABLE Students ( StudentID INT UNIQUE, FirstName VARCHAR(50), LastName VARCHAR(50) ); -
Check Constraint:
-
A check constraint enforces a specific condition or range of values on a column.
- It allows you to define custom rules that data in a column must adhere to.
Example:
sql
-
CREATE TABLE Orders ( OrderID INT, OrderDate DATE, TotalAmount DECIMAL(10, 2), CHECK (TotalAmount >= 0) ); -
Foreign Key Constraint:
-
A foreign key constraint establishes a relationship between two tables by linking a column in one table to a primary key or unique key in another table.
- It ensures referential integrity by enforcing that values in the referencing column match values in the referenced column.
Example:
sql
-
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) ); -
Not Null Constraint:
-
A not null constraint ensures that a column does not contain NULL values.
- It enforces that every row must have a value in the specified column.
Example:
sql
-
CREATE TABLE Products ( ProductID INT PRIMARY KEY, ProductName VARCHAR(100) NOT NULL, Price DECIMAL(10, 2) ); -
Default Constraint:
-
A default constraint provides a default value for a column when no value is specified during an INSERT operation.
- It is used to ensure that a column always contains a value, even if one is not explicitly provided.
Example:
sql
-
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName VARCHAR(50), LastName VARCHAR(50), HireDate DATE DEFAULT '2023-01-01' ); -
15. With suitable examples explain use of aggregate functions
-
Aggregate functions in SQL are used to perform calculations on sets of values and return a single value as the result. These functions are often used in conjunction with the
GROUP BYclause to perform calculations on grouped data. Here are some common aggregate functions with suitable examples:-
COUNT():
- The
COUNT()function returns the number of rows in a result set.
Example: Count the number of orders for each customer.
sql
- The
-
SELECT CustomerID, COUNT(OrderID) AS OrderCount FROM Orders GROUP BY CustomerID;-
SUM():
-
The
SUM()function calculates the sum of all values in a numeric column.
Example: Calculate the total sales amount for a given product.
sql
-
SELECT ProductName, SUM(Price * Quantity) AS TotalSales FROM Sales WHERE ProductID = 101 -
AVG():
-
The
AVG()function computes the average of a set of values in a numeric column.
Example: Find the average salary of employees in a department.
sql
-
SELECT Department, AVG(Salary) AS AvgSalary FROM Employees GROUP BY Department; -
MIN():
-
The
MIN()function returns the minimum (lowest) value in a column.
Example: Find the lowest temperature recorded in a weather database.
sql
-
SELECT MIN(Temperature) AS LowestTemperature FROM WeatherData; -
MAX():
-
The
MAX()function returns the maximum (highest) value in a column.
Example: Find the highest score in a test scores table.
sql
-
SELECT MAX(Score) AS HighestScore FROM TestScores; -
16. Elaborate in detail DDL & DML commands with suitable examples
-
DDL (Data Definition Language):
DDL commands are used to define, manage, and control the structure of a database, including creating, altering, and deleting database objects such as tables, indexes, and constraints. DDL commands are not used for manipulating data within the database. Here are some common DDL commands with examples:
-
CREATE TABLE:
- The
CREATE TABLEcommand is used to create a new table in the database.
Example:
sql
- The
-
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName VARCHAR(50), LastName VARCHAR(50), Department VARCHAR(50) );-
ALTER TABLE:
-
The
ALTER TABLEcommand is used to modify an existing table, such as adding, modifying, or deleting columns.
Example:
sql
-
ALTER TABLE Employees ADD Salary DECIMAL(10, 2); -
DROP TABLE:
-
The
DROP TABLEcommand is used to delete an existing table and remove all its data and structure.
Example:
sql
-
DROP TABLE Employees; -
CREATE INDEX:
-
The
CREATE INDEXcommand is used to create an index on one or more columns of a table, which improves the performance of data retrieval operations.
Example:
sql
-
CREATE INDEX idx_last_name ON Employees(LastName); -
DROP INDEX:
-
The
DROP INDEXcommand is used to remove an existing index from a table.
Example:
sql
-
DROP INDEX idx_last_name; -
CREATE VIEW:
-
The
CREATE VIEWcommand is used to create a virtual table that is defined by a SELECT statement. Views are used to simplify complex queries.
Example:
sql
-
CREATE VIEW HighSalaryEmployees AS SELECT * FROM Employees WHERE Salary > 50000; -
ALTER VIEW:
-
The
ALTER VIEWcommand is used to modify an existing view.
Example:
sql
-
ALTER VIEW HighSalaryEmployees AS SELECT * FROM Employees WHERE Salary > 60000; -
DROP VIEW:
-
The
DROP VIEWcommand is used to delete an existing view.
Example:
sql
-
-
DROP VIEW HighSalaryEmployees;
DML (Data Manipulation Language):
DML commands are used to manipulate data stored in the database. They include commands for inserting, updating, and deleting data in tables, as well as retrieving data from tables. Here are some common DML commands with examples:
-
SELECT:
- The
SELECTcommand retrieves data from one or more tables.
Example:
sql
- The
-
SELECT FirstName, LastName FROM Employees WHERE Department = 'Sales';-
INSERT INTO:
-
The
INSERT INTOcommand is used to add new rows to a table.
Example:
sql
-
INSERT INTO Employees (EmployeeID, FirstName, LastName, Department) VALUES (101, 'John', 'Doe', 'HR'); -
UPDATE:
-
The
UPDATEcommand is used to modify existing data in a table.
Example:
sql
-
UPDATE Employees SET Salary = Salary * 1.1 WHERE Department = 'Engineering'; -
17. What types of SQL subqueries do you know?Explain with suitable example
-
In SQL, a subquery (also known as a nested query or inner query) is a query that is embedded within another query. Subqueries are used to retrieve data that will be used as a condition or value in the main query. There are several types of SQL subqueries based on their usage within the main query. Here are some common types of SQL subqueries with suitable examples:
-
Scalar Subquery:
- A scalar subquery is a subquery that returns a single value. It can be used in places where a single value is expected, such as in the SELECT clause, WHERE clause, or HAVING clause.
Example: Find employees whose salary is greater than the average salary in the department.
sql
-
SELECT EmployeeName FROM Employees WHERE Salary > (SELECT AVG(Salary) FROM Employees WHERE Department = 'IT');-
Single-Row Subquery:
-
A single-row subquery returns one row and is typically used in a comparison operation (e.g., =, >, <) in the WHERE clause.
Example: Retrieve information about the highest-paid employee.
sql
-
SELECT * FROM Employees WHERE Salary = (SELECT MAX(Salary) FROM Employees); -
Multiple-Row Subquery:
-
A multiple-row subquery returns multiple rows and is used with operators that can handle multiple values, such as the IN or EXISTS operator.
Example: Find employees who have placed orders.
sql
-
SELECT EmployeeName FROM Employees WHERE EmployeeID IN (SELECT DISTINCT EmployeeID FROM Orders); -
Correlated Subquery:
-
A correlated subquery references columns from the outer query, and the subquery is executed for each row processed by the outer query.
Example: Find employees whose salary is greater than the average salary in their department using a correlated subquery.
sql
-
SELECT EmployeeName FROM Employees e WHERE Salary > (SELECT AVG(Salary) FROM Employees WHERE Department = e.Department); -
Table Subquery (Derived Table):
-
A table subquery, also known as a derived table, is a subquery that returns a result set, and it can be used as a table within the main query.
Example: List employees who have placed orders, along with order details.
sql
-
SELECT e.EmployeeName, o.OrderID, o.OrderDate FROM Employees e JOIN (SELECT EmployeeID, OrderID, OrderDate FROM Orders) o ON e.EmployeeID = o.EmployeeID; -
18. Define following terms :Primary key, Foreign key ,Unique key in brief
-
Primary Key:
- A primary key is a column or set of columns in a database table that uniquely identifies each row (record) in the table.
- It enforces the uniqueness and integrity of the data by ensuring that no two rows can have the same values in the primary key column(s).
- Primary keys are used to establish relationships between tables and are crucial for maintaining data consistency and integrity.
-
Foreign Key:
-
A foreign key is a column or set of columns in one table that is used to establish a link or relationship between the data in two tables.
- It creates referential integrity by ensuring that values in the foreign key column(s) of one table correspond to values in the primary key column(s) of another table.
- Foreign keys are used to maintain relationships between tables, allowing you to retrieve related data from different tables.
-
Unique Key:
-
A unique key is a constraint applied to one or more columns in a table to enforce the uniqueness of values in those columns.
- Unlike a primary key, a unique key allows one NULL value, but it ensures that all non-NULL values are unique.
- Unique keys are often used to enforce the uniqueness of data in columns where a primary key is not suitable, such as in cases where NULL values are allowed or in tables with alternate keys.
19. Explain CRUD operations in DBMS in detail with suitable examples
-
CRUD is an acronym that stands for Create, Read, Update, and Delete. These four operations represent the basic functions and interactions that can be performed on data in a Database Management System (DBMS). They are fundamental to database systems and are used to manipulate data in tables. Let's explain each CRUD operation in detail with suitable examples:
-
Create (C):
- The "Create" operation involves inserting new records or rows into a database table.
Example: Suppose you have a table called "Students" with columns "StudentID," "FirstName," and "LastName." To create a new record for a student:
sql
-
INSERT INTO Students (StudentID, FirstName, LastName) VALUES (101, 'John', 'Doe');-
Read (R):
-
The "Read" operation involves retrieving and querying data from a database table.
Example: To read (retrieve) all students from the "Students" table:
sql
-
SELECT * FROM Students; -
Update (U):
-
The "Update" operation is used to modify existing records in a database table.
Example: To update the last name of a specific student (e.g., StudentID 101):
sql
-
UPDATE Students SET LastName = 'Smith' WHERE StudentID = 101; -
Delete (D):
-
The "Delete" operation is used to remove records from a database table.
Example: To delete a specific student (e.g., StudentID 101) from the "Students" table:
sql
-
DELETE FROM Students WHERE StudentID = 101; -
20. Describe Data mining process in detail with suitable example
Data mining is a process of discovering patterns, trends, correlations, or useful information from large volumes of data. It involves using various techniques and tools to extract valuable insights and knowledge from data. The data mining process typically consists of several stages. Here, I'll describe the data mining process in detail with a suitable example:
Data Mining Process:
-
Data Collection:
- The first step in the data mining process is collecting and gathering relevant data from various sources. This data can be structured or unstructured and may come from databases, text documents, sensor data, web logs, and more.
Example: Let's consider a retail company that wants to analyze its sales data. The data may include information on products, sales transactions, customer demographics, and more.
-
Data Preprocessing:
- Once data is collected, it often requires preprocessing. This involves cleaning the data by handling missing values, removing duplicates, and resolving inconsistencies. Data transformation may also be needed, such as normalizing numerical values or encoding categorical variables.
Example: In the retail sales data, there may be missing values for some product prices, and some product names might have typos or variations that need to be standardized.
-
Data Exploration:
- Data exploration involves understanding the data's characteristics and structure. This is often done through data visualization and summary statistics to identify patterns, outliers, or potential relationships.
Example: Visualizing sales data may reveal that certain products have seasonal sales patterns, or there might be customer segments with different purchasing behaviors.
-
Feature Selection:
- In this step, you choose which attributes or features to use for analysis. Not all features in the dataset may be relevant to the data mining goals.
Example: You may decide to focus on attributes like product category, customer location, and purchase date to understand sales patterns.
-
Model Building:
- This is the core of the data mining process. Various data mining techniques are applied to build predictive models, identify patterns, or make inferences from the data. Common techniques include decision trees, clustering, regression, and neural networks.
Example: You may use a decision tree algorithm to predict which products are likely to sell well based on historical sales data and attributes like product category, price, and season.
-
Model Evaluation:
- Models need to be evaluated to assess their quality and performance. This often involves using techniques like cross-validation, calculating metrics (e.g., accuracy, precision, recall), and comparing models to select the best one.
Example: You may evaluate the decision tree model's accuracy in predicting product sales and compare it to other models like linear regression.
-
Model Deployment:
- Once a model is selected, it can be deployed for practical use. This may involve integrating it into business processes, applications, or decision support systems.
Example: The sales prediction model could be integrated into the company's inventory management system to optimize stock levels.
-
Model Interpretation and Reporting:
- The results of data mining are often interpreted and presented in a way that is understandable to stakeholders. Reports and visualizations can communicate the insights gained from the data mining process.
Example: A report may show that certain product categories have a strong correlation with sales during specific seasons, helping the company make informed marketing and inventory decisions.
-
Maintenance and Monitoring:
- After deployment, models and systems need to be monitored and maintained. Data patterns may change over time, requiring periodic updates to the models and processes.
21. Brief in detail: NoSQL database
NoSQL databases (which stands for "not only SQL") are a family of database management systems that provide a flexible and scalable approach to data storage and retrieval. Unlike traditional relational databases, NoSQL databases do not rely on a fixed schema and are well-suited for handling large volumes of unstructured or semi-structured data. They are often used in modern, distributed, and rapidly evolving applications. Here, I'll provide a detailed overview of NoSQL databases:
Key Characteristics of NoSQL Databases:
-
Schema-less: NoSQL databases do not enforce a fixed schema for data. Each record or document in a NoSQL database can have its own structure, allowing for more flexible and dynamic data modeling.
-
Non-relational: Unlike relational databases, NoSQL databases do not use the traditional tabular structure with tables, rows, and columns. They use various data models, such as key-value, document, column-family, and graph, depending on the type of NoSQL database.
-
Scalability: NoSQL databases are designed to scale horizontally, making it easier to handle large amounts of data and traffic. They are suitable for distributed and cloud-based architectures.
-
High Performance: NoSQL databases often provide fast read and write operations, making them ideal for applications that require low-latency access to data.
-
Distributed: Many NoSQL databases are designed for distributed data storage and retrieval, providing fault tolerance and high availability.
-
No SQL Query Language: While traditional SQL databases use SQL for querying, NoSQL databases may use a variety of query languages, depending on the database type. Some NoSQL databases, like document stores, provide powerful query capabilities.
Types of NoSQL Databases:
-
Document Stores: These databases store data in semi-structured documents, such as JSON or XML. Examples include MongoDB and CouchDB.
-
Key-Value Stores: Data is stored as key-value pairs, which is a simple and efficient way to manage data. Examples include Redis and Amazon DynamoDB.
-
Column-family Stores: These databases organize data into column families and columns, suitable for handling large amounts of data with high write throughput. Examples include Apache Cassandra and HBase.
-
Graph Databases: These databases are optimized for managing and querying graph-like data structures. Examples include Neo4j and Amazon Neptune.
Use Cases for NoSQL Databases:
-
Big Data: NoSQL databases are well-suited for handling large volumes of data generated by big data applications.
-
Real-time Analytics: NoSQL databases can provide low-latency access to data, making them suitable for real-time analytics and reporting.
-
Content Management Systems (CMS): NoSQL databases are used to manage and serve content for websites and digital media.
-
IoT (Internet of Things): NoSQL databases can handle data generated by IoT devices, including sensor data and event logs.
-
User Profile Management: NoSQL databases are used to store and manage user profiles and preferences in applications.
Example: MongoDB (Document Store)
MongoDB is a popular NoSQL database that uses a document-oriented model. It stores data in BSON (Binary JSON) format, allowing for flexible data structures within each document. Here's a basic example of how data might be stored in MongoDB:
json
{
"_id": 1,
"name": "John Doe",
"age": 30,
"email": "johndoe@email.com",
"address": {
"street": "123 Main St",
"city": "Anytown",
"zip": "12345"
}
}
In this example, the data doesn't follow a rigid tabular structure, and each document can have different fields.
22. Elaborate in detail recent advancements in database management system
Recent advancements in database management systems (DBMS) have been driven by the need to handle increasingly complex data, support real-time analytics, and adapt to modern application architectures. Here are some of the key advancements in the field of DBMS:
-
NoSQL and NewSQL Databases:
- NoSQL databases (e.g., MongoDB, Cassandra) continue to gain popularity for handling unstructured and semi-structured data. They offer flexible data models and scalability.
- NewSQL databases (e.g., CockroachDB, Spanner) combine the scalability of NoSQL with the transactional consistency of traditional SQL databases.
-
Multi-Model Databases:
-
Multi-model databases (e.g., ArangoDB, Couchbase) allow developers to work with different data models (e.g., key-value, document, graph) within a single database.
-
Time-Series Databases:
-
Time-series databases (e.g., InfluxDB, Prometheus) are designed to efficiently store and query time-series data, which is critical for IoT, monitoring, and financial applications.
-
Graph Databases:
-
Graph databases (e.g., Neo4j) have improved their performance and scalability for handling complex relationships, making them ideal for social networks, recommendation engines, and fraud detection.
-
In-Memory Databases:
-
In-memory databases (e.g., Redis, MemSQL) have become more accessible, providing ultra-fast data access and analysis. They are used for real-time analytics and caching.
-
Serverless Databases:
-
Serverless databases (e.g., AWS Aurora Serverless, Firebase) automatically scale and manage resources, making them easy to use and cost-effective.
-
Cloud-Native Databases:
-
Databases are increasingly designed for cloud-native environments, with features like auto-scaling, pay-as-you-go pricing, and serverless computing.
-
Blockchain Databases:
-
Blockchain databases (e.g., BigchainDB) integrate blockchain technology into database management, ensuring transparency, immutability, and security for applications like supply chain management and financial services.
-
AI and Machine Learning Integration:
-
DBMS are integrating AI and machine learning for tasks like query optimization, anomaly detection, and predictive analytics, allowing for smarter data management.
-
Data Privacy and Security:
-
Advanced encryption, access control, and data anonymization techniques have been developed to address the growing concerns about data privacy and security.
-
Geospatial Databases:
-
Geospatial databases (e.g., PostGIS, MongoDB GeoSpatial) have improved their support for location-based data and queries, benefiting applications like mapping and logistics.